





近日,广州国家实验室李亦学研究员团队在Genome Biology发表题为Benchmarking LLM-based agents for single-cell omics analysis的研究论文,系统构建了面向单细胞组学分析的LLM智能体基准测试体系,从多模型、多框架、多任务维度出发,针对AI智能体在真实生物信息学场景中的表现进行全面量化评估,系统揭示了不同模型与框架间的性能差异、关键瓶颈及优化路径,为“AI Agent + Bio-OS”的融合研究奠定了重要基础。
随着单细胞组学与空间组学技术快速发展,生物医学数据呈指数级增长,传统依赖人工选择算法与调参的分析范式正面临效率低、可扩展性差与知识更新滞后的挑战。近年来,AI Agent凭借自然语言理解、自主规划、多工具调用与代码执行,逐步实现“假设—验证—迭代”的科研闭环。然而,尽管以Biomni为代表的系统已初显潜力,不同模型与智能体框架在真实任务中的性能表现仍缺乏系统性评估,成为制约其进一步应用的关键问题。
针对这一挑战,研究团队构建了一套标准化、多维度的基准评测体系。首先,在平台层面,设计统一的智能体执行框架,兼容ReAct、LangGraph、AutoGen三类主流架构,并集成包括GPT-4.1、Grok3-beta、DeepSeek-R1在内的8种大语言模型,实现输入、执行与评估流程的全面标准化。其次,在评估体系上,突破传统单一成功率指标,构建涵盖18项细粒度指标的多维评测框架,从代码生成质量、任务执行效率、知识检索能力及结果可靠性等多个维度进行系统打分。最后,在任务设计上,选取50个真实世界单细胞分析任务,覆盖细胞注释、批次校正、空间解卷积、轨迹推断等12类核心应用场景,确保评测结果具有实际科研意义。
随着单细胞组学与空间组学技术快速发展,生物医学数据呈指数级增长,传统依赖人工选择算法与调参的分析范式正面临效率低、可扩展性差与知识更新滞后的挑战。近年来,AI Agent凭借自然语言理解、自主规划、多工具调用与代码执行,逐步实现“假设—验证—迭代”的科研闭环。然而,尽管以Biomni为代表的系统已初显潜力,不同模型与智能体框架在真实任务中的性能表现仍缺乏系统性评估,成为制约其进一步应用的关键问题。
针对这一挑战,研究团队构建了一套标准化、多维度的基准评测体系。首先,在平台层面,设计统一的智能体执行框架,兼容ReAct、LangGraph、AutoGen三类主流架构,并集成包括GPT-4.1、Grok3-beta、DeepSeek-R1在内的8种大语言模型,实现输入、执行与评估流程的全面标准化。其次,在评估体系上,突破传统单一成功率指标,构建涵盖18项细粒度指标的多维评测框架,从代码生成质量、任务执行效率、知识检索能力及结果可靠性等多个维度进行系统打分。最后,在任务设计上,选取50个真实世界单细胞分析任务,覆盖细胞注释、批次校正、空间解卷积、轨迹推断等12类核心应用场景,确保评测结果具有实际科研意义。
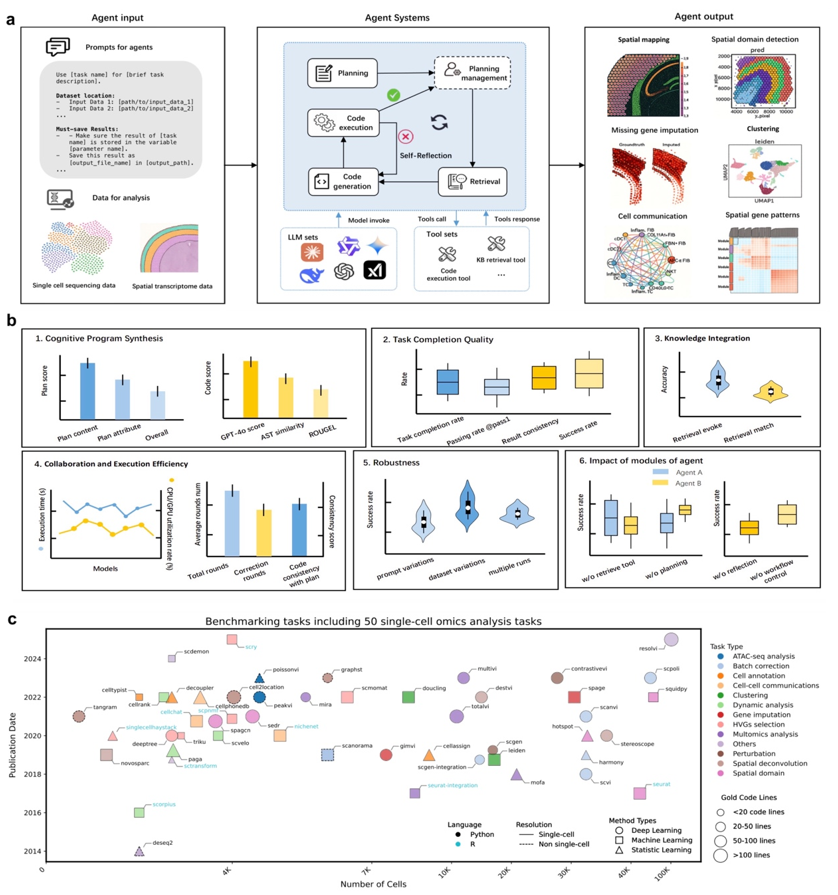 图1 基准测试平台:系统集成多种LLM、工具,并兼容多种智能体框架
图1 基准测试平台:系统集成多种LLM、工具,并兼容多种智能体框架 研究结果表明,不同模型与智能体框架之间存在显著性能差异。其中,Grok3-beta在代码生成质量、任务成功率及跨框架适配性方面表现最优。进一步分析发现,代码生成能力是决定任务成败的核心因素,大多数失败源于执行阶段代码错误,而非规划不足。在架构层面,单智能体框架ReAct在知识检索准确性上更具优势,但交互成本较高;多智能体框架则通过角色分工,在稳定性与执行效率方面表现更优。这一结果提示,未来优化方向应更加聚焦于代码生成与执行能力的提升。
在评估指标方面,研究提出“结果一致性”作为统一衡量标准,并验证其与任务特定生物学指标之间具有较强正相关性,说明该指标可作为跨任务比较的有效代理。同时,通过消融实验发现,自我反思模块对性能提升贡献最大,其次为检索增强模块,而工作流控制模块影响相对有限。此外,系统在不同数据集及多次运行中表现出良好的稳定性与鲁棒性。
针对失败案例的系统分析进一步揭示了当前智能体的关键瓶颈,包括长上下文处理能力不足、知识获取失败及指令理解偏差等问题。其中,长上下文处理失败对整体性能影响最为显著,往往导致关键信息遗漏并在后续步骤中放大错误。
值得强调的是,该基准体系的构建依托广州国家实验室Bio-OS平台的强大支撑。Bio-OS作为面向生命科学的大规模数据与计算基础设施,为各类生物信息学任务提供高效、可扩展的云计算资源与标准化工作流环境。同时,Bio-OS通过统一接口与任务编排能力,使AI智能体能够无缝调用多模态数据与复杂分析工具,实现自动化科研流程的高效执行。
这种“AI Agent + Bio-OS”的协同模式,不仅显著降低了生物信息分析的技术门槛,也为AI4Science提供了关键基础设施:基准体系回答“如何评估AI能力”,而Bio-OS解决“如何规模化应用AI能力”,共同构建从方法评测到科研落地的闭环生态。
本研究由广州国家实验室主导完成,广州国家实验室李亦学研究员、沈荣波副研究员,飞鹤研究院张旭光、汤臣倍健营养健康研究院贺瑞坤为共同通讯作者。刘洋博士、周露博士为共同第一作者,本研究得到了广州国家实验室科研任务专项项目等项目的资助。
论文链接:https://link.springer.com/article/10.1186/s13059-026-03998-z
在评估指标方面,研究提出“结果一致性”作为统一衡量标准,并验证其与任务特定生物学指标之间具有较强正相关性,说明该指标可作为跨任务比较的有效代理。同时,通过消融实验发现,自我反思模块对性能提升贡献最大,其次为检索增强模块,而工作流控制模块影响相对有限。此外,系统在不同数据集及多次运行中表现出良好的稳定性与鲁棒性。
针对失败案例的系统分析进一步揭示了当前智能体的关键瓶颈,包括长上下文处理能力不足、知识获取失败及指令理解偏差等问题。其中,长上下文处理失败对整体性能影响最为显著,往往导致关键信息遗漏并在后续步骤中放大错误。
值得强调的是,该基准体系的构建依托广州国家实验室Bio-OS平台的强大支撑。Bio-OS作为面向生命科学的大规模数据与计算基础设施,为各类生物信息学任务提供高效、可扩展的云计算资源与标准化工作流环境。同时,Bio-OS通过统一接口与任务编排能力,使AI智能体能够无缝调用多模态数据与复杂分析工具,实现自动化科研流程的高效执行。
这种“AI Agent + Bio-OS”的协同模式,不仅显著降低了生物信息分析的技术门槛,也为AI4Science提供了关键基础设施:基准体系回答“如何评估AI能力”,而Bio-OS解决“如何规模化应用AI能力”,共同构建从方法评测到科研落地的闭环生态。
本研究由广州国家实验室主导完成,广州国家实验室李亦学研究员、沈荣波副研究员,飞鹤研究院张旭光、汤臣倍健营养健康研究院贺瑞坤为共同通讯作者。刘洋博士、周露博士为共同第一作者,本研究得到了广州国家实验室科研任务专项项目等项目的资助。
论文链接:https://link.springer.com/article/10.1186/s13059-026-03998-z
